
Stellt euch vor, ihr könntet über einen Besucher eurer Webseite alle relevanten Informationen in Erfahrung bringen (Name, Geschlecht, Vorlieben, etc.). Dank den sozialen Netzwerken sind diese Informationen zumindest zum Teil öffentlich verfügbar (z.B. durch Facebook- oder Google+ Profile). Allerdings müsste man dazu wissen, ob ein Besucher ein solches Profil besitzt und – hier wird es kompliziert – wie dieses lautet.
Angestoßen durch den Artikel When Security Generates Insecurity (Hat Tip to Michael, der die Abfrage des Login-Status implementiert hat) habe ich herausgefunden, dass es möglich ist, die Facebook Profil-URL eines Users durch die Ausnutzung einer Lücke in Google Chrome herauszufinden.
Das folgende Video zeigt ein Proof of Concept dazu (hier geht’s zu Live-Version)
Deanonymizing Facebook Users By CSP Bruteforcing
Inhaltsverzeichnis
- Inhaltsverzeichnis
- Related Work: Bereits dokumenierte Techniken zur Deanonymisierung
- Mein Lösungsansatz: Bruteforcing von URLs durch Content-Security-Policy Restriktionen
- Deanonymisierung durch Prüfung von Profil-URLs
- Binäre Suche über Profil-URLs
- Schwergewicht: Hohes Datenvolumen beim Bruteforcing
- Vorqualifizierung von Facebook Profil URLs
- Datenbasis: Beschaffung von Facebook Profil-URLs und weiteren Daten
- Grundproblem: Browser-Implementierung des Content-Security-Policy Headers
- TL;DR: CSP-Deanonymisierung funktioniert nur in Ausnahmefällen
- Proof of Concept – Tool zur Deanonymisierung in der Praxis
- Scope, How-to-fix und Responsible Disclosure
- Fazit: Viel gelernt aber nixnur wenig gewonnen
Related Work: Bereits dokumenierte Techniken zur Deanonymisierung
Viele gute Informationen und Denkanstöße liefert das Paper A Practical Attack to De-Anonymize Social Network Users. Darin wird beschrieben, wie durch eine Kombination aus History Stealing und einem Fingerprint (gebildet aus Gruppenzugehörigkeiten) das Xing-Profil eines Users reengineered werden konnte. Besonders interessant sind die verschiedenen Vorgensweisen zur Extraktion von Profil-Informationen sozialer Netzwerke, die auch jetzt noch funktionieren. „Leider“ ist es seit 2010 nicht mehr möglich, History-Stealing Attacken auszuführen (siehe Preventing attacks on a user’s history through CSS :visited selectors) – außer man provoziert eine Nutzerinteraktion (dann wäre zum Beispiel History theft with CSS Boolean algebra ein möglicher Ansatz), aber das skaliert dann nicht mehr.
Die I know … Serie von Jeremiah Grossman ist generell eine gute Inspirationsquelle. Besonders hervorheben möchte ich folgende Beiträge:
- I Know Your Name, and Probably a Whole Lot More
- Nutzer klickt auf ein transparentes Like-Button-Iframe und ein Script holt sich sofort den neusten ‚Fan‘ der Seite
- I Know Who You Work For
- Fehlerprüfung beim Aufruf von gesperrten Ressourcen am Beispiel von Intranet-URLs
- Breaking Browsers: Hacking Auto-Complete
- Simulierung von Tastatur-Events zum Auslesen von Auto-Complete-Informationen
Mein Lösungsansatz: Bruteforcing von URLs durch Content-Security-Policy Restriktionen
Bei meinem Lösungsansatz nutze ich das Verhalten des Browsers beim Aufruf einer URL aus, wenn diese auf Grund der CSP Restriktionen nicht aufgerufen werden darf. CSP steht für Content Security Policy und dient dazu, die Ressourcen die eine Webseite nachlädt (CSS, Bilder, JS, etc.) auf vorab definierte Quellen zu beschränken. Dadurch soll das Einschleusen von Schadcode unterbunden werden. Es gibt noch ein paar weitere interessante Eigenschaften (wie z.B. die report-uri) – dazu verweise ich gerne auf An Introduction to Content Security Policy – eine gute und ausführliche Einleitung zur Content Security Policy.
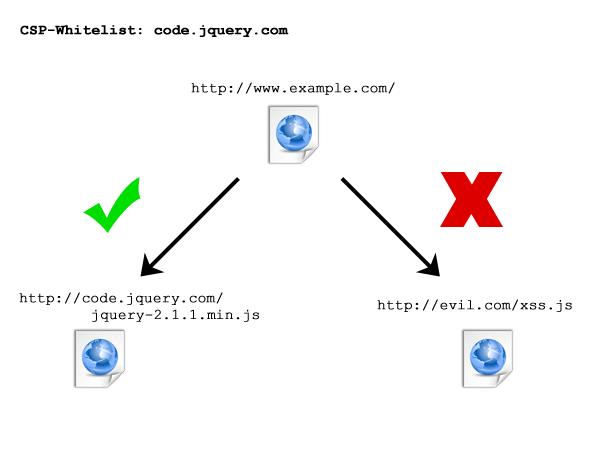
Code-Beispiel zur Funktionsweise des CSP Headers:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<!-- Erlaube externe Scripte nur von dem Host code.jquery.com -->
<meta http-equiv="Content-Security-Policy"
content="default-src 'self' 'unsafe-inline';
script-src 'unsafe-inline'
code.jquery.com" />
</head>
<body>
<!-- Dieser Aufruf ist erfolgreich -->
<script src="https://code.jquery.com/jquery-2.1.1.min.js" />
<!-- Dieser Aufruf wird blockiert -->
<script src="https://evil.com/xss.js" />
</body>
</html>
Durch den geschickten Einsatz des CSP Headers kann ich testen, ob ein URL aufrufbar ist und das wird vor allem dann interessant, wenn ich aus dieser URL Rückschlüsse auf die Identität des Users ziehen kann.
Deanonymisierung durch Prüfung von Profil-URLs
Findet man eine URL („Original-URL“), die eine Weiterleitung auf Basis privater Informationen (z.B. Login-Status) erzeugt, ließe sich das Weiterleitungsziel („Target-URL“) damit ermitteln. Dazu müssen sowohl die Original- als auch Target-URL im CSP Header erlaubt werden.
Hinweis: Die Weiterleitung muss über den Location-Header erfolgen. JavaScript, Meta-Refresh und andere Möglichkeiten, bei denen der Browser zunächst die komplette Seite rendern muss, funktionieren nicht!
Beispiele für solche URLs:
- https://www.facebook.com/me leitet auf das Facebook Profil weiter
- https://plus.google.com/me leitet auf das Google+ Profil weiter
- https://www.youtube.com/user/ leitet auf den Youtube Kanal weiter
- https://www.xing.com/profile leitet auf das Xing Profil weiter
Ist man nicht eingeloggt, leiten diese URLs wie folgt weiter:
- https://www.facebook.com/login.php
- https://accounts.google.com/ServiceLogin (Google+ and Youtube)
- https://login.xing.com/continue
Login-Status prüfen
Zur Verdeutlichung, wie ich diese Informationen zur Deanonymisierung nutzen kann, folgt ein einfaches Beispiel:
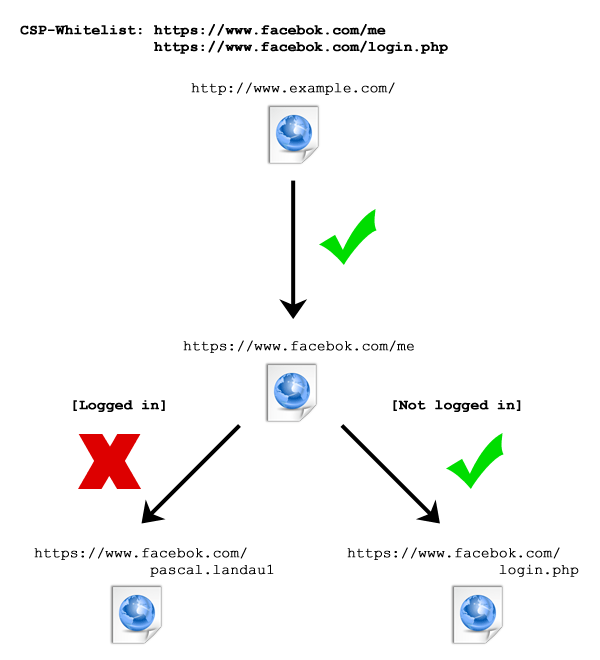
- Erlaube den Zugriff auf https://www.facebook.com/me und https://www.facebook.com/login.php via CSP Header
- Erzeuge eine <script>-Element mit src=https://www.facebook.com/me
-
- Wäre ich bei Facebook eingeloggt, würde https://www.facebook.com/me eine Weiterleitung auf auf https://www.facebook.com/pascal.landau1 auslösen und der Browser einen fehlgeschlagenen Script-Aufruf melden.
- Wäre ich nicht bei Facebook eingeloggt, würde https://www.facebook.com/me eine Weiterleitung auf https://www.facebook.com/login.php? auslösen und der Browser einen erfolgreichen Script-Aufruf melden.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<!--
Erlaube externe Scripte nur von den URLs
https://www.facebook.com/me und https://www.facebook.com/login.php
-->
<meta http-equiv="Content-Security-Policy"
content="default-src 'self' 'unsafe-inline';
script-src 'unsafe-inline'
https://www.facebook.com/me
https://www.facebook.com/login.php" />
</head>
<body>
<!--
b) Bin ich eingeloggt, ist dieser Aufruf _nicht_ erfolgreich.
https://www.facebook.com/me liefert einen 3XX Status Code
mit Location Header auf
https://www.facebook.com/pascal.landau1 und diese URL steht
_nicht_ auf der CSP-Whitelist.
b) Bin ich _nicht_ eingeloggt, ist dieser Aufruf erfolgreich.
https://www.facebook.com/me liefert einen 3XX Status Code
mit Location Header auf
https://www.facebook.com/login.php und beide URLs stehen
auf der CSP-Whitelist.
-->
<script src="https://www.facebook.com/me" />
</body>
</html>
Okay, jetzt weiß ich zumindest ob ich bei Facebook eingeloggt bin (a) oder nicht (b) – allerdings kenne ich meine Profil-URL noch nicht (denn ich weiß bisher nur, ob der Aufruf von https://www.facebook.com/login.php fehlgeschlagen ist oder erfolgreich war).
Profil-URL prüfen
Durch eine Modifzierung des Beispiels kann ich aber auch diese Information bekommen:
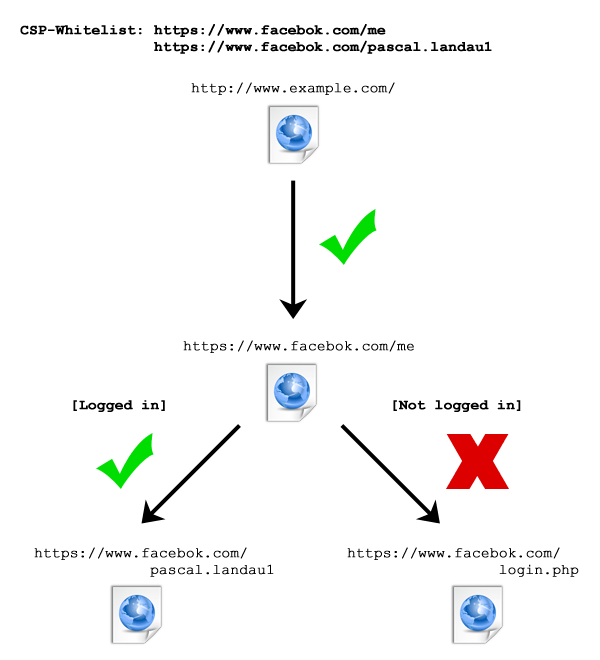
- Erlaube den Zugriff auf https://www.facebook.com/me und https://www.facebook.com/pascal.landau1 via CSP Header
- Erzeuge eine <script>-Element mit src=https://www.facebook.com/me
-
- Wäre ich als Pascal Landau bei Facebook eingeloggt, würde https://www.facebook.com/me eine Weiterleitung auf https://www.facebook.com/pascal.landau1 auslösen und der Browser einen erfolgreichen Script-Aufruf melden.
- Wäre ich nicht als Pascal Landau sondern als jemand anderes bei Facebook eingeloggt, würde https://www.facebook.com/me eine Weiterleitung auf ein anderes Facebook Profil auslösen und der Browser einen fehlgeschlagenen Script-Aufruf melden.
- Wäre ich nicht bei Facebook eingeloggt, würde https://www.facebook.com/me eine Weiterleitung auf https://www.facebook.com/login.php?… auslösen und der Browser einen fehlgeschlagenen Script-Aufruf melden.
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<!--
Erlaube externe Scripte nur von den URLs
https://www.facebook.com/me und
https://www.facebook.com/pascal.landau1
-->
<meta http-equiv="Content-Security-Policy"
content="default-src 'self' 'unsafe-inline';
script-src 'unsafe-inline'
https://www.facebook.com/me
https://www.facebook.com/pascal.landau1" />
</head>
<body>
<!--
a) Bin ich _als Pascal Landau_ eingeloggt, ist dieser Aufruf erfolgreich.
https://www.facebook.com/me liefert einen 3XX Status Code
mit Location Header auf
https://www.facebook.com/pascal.landau1 und beide URLs stehen
auf der CSP-Whitelist.
b) Bin ich _als ein anderer Nutzer_ eingeloggt, ist dieser Aufruf nicht erfolgreich.
https://www.facebook.com/me liefert einen 3XX Status Code
mit Location Header auf
https://www.facebook.com/[some.username] und diese URL ist
_nicht_ auf der CSP-Whitelist.
c) Bin ich _nicht als Pascal Landau_ eingeloggt, ist dieser Aufruf _nicht_ erfolgreich.
https://www.facebook.com/me liefert einen 3XX Status Code
mit Location Header auf
https://www.facebook.com/login.php und diese URL steht
_nicht_ auf der CSP-Whitelist.
-->
<script src="https://www.facebook.com/me" />
</body>
</html>
Soweit so gut – allerdings hat das Ganze einen entscheidenden Nachteil: Ich muss bereits vor der Prüfung wissen, welche URLs ich im CSP Header angeben muss und deshalb im Prinzip alle möglichen Profil-URLs einzeln durchprobieren. Wenn ich stupide Bruteforce ist das ein HTTP-Request pro zu prüfender Profil-URL. Bedenkt man nun, dass Facebook über eine Milliarde User hat wird klar, dass das keinen Sinn macht…
Binäre Suche über Profil-URLs
Zum Glück lassen sich aber mit einem Aufruf gleich mehrere URLs prüfen. Diese kann ich durch die geschickte Kontruktion der nachfolgenden Requests soweit eingeschränken, dass nur noch genau eine URL übrig bleibt. Dadurch lässt sich die Anzahl der HTTP-Requests massiv verringern, wie folgendes Beispiel zeigt:
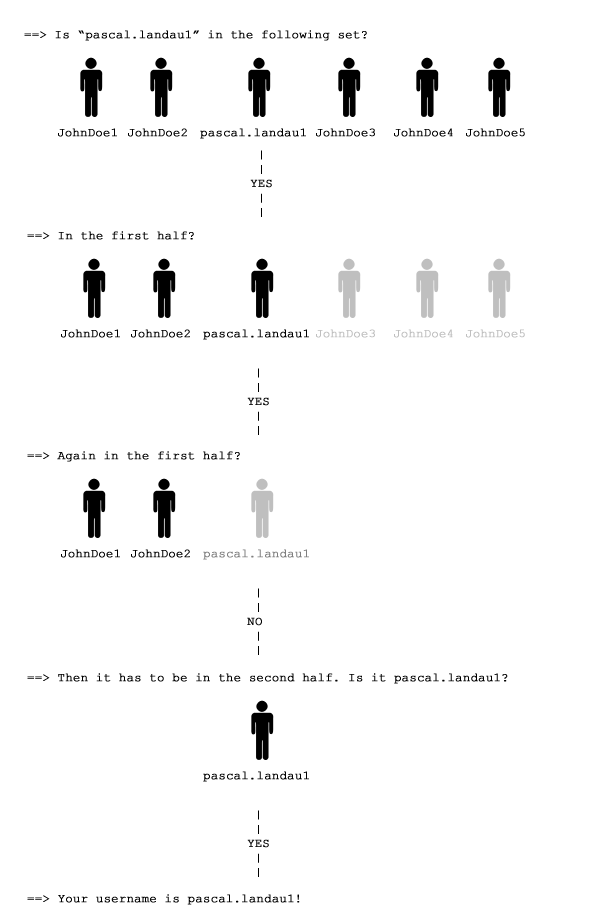
Nehmen wir an, es gäbe 6 zu prüfende Profil-URLs. Nehmen wir weiter an, ich bin als Pascal Landau eingeloggt und habe die Profil-URL https://www.facebook.com/pascal.landau1
- Erlaube den Zugriff auf https://www.facebook.com/me und die folgenden 6 Profil-URLs via CSP Header
(1) https://www.facebook.com/JohnDoe1
(2) https://www.facebook.com/JohnDoe2
(3) https://www.facebook.com/pascal.landau1
(4) https://www.facebook.com/JohnDoe3
(5) https://www.facebook.com/JohnDoe4
(6) https://www.facebook.com/JohnDoe5 - Erzeuge eine <script>-Element mit src=https://www.facebook.com/me
- https://www.facebook.com/me erzeugt eine Weiterleitung auf https://www.facebook.com/pascal.landau1 und der Browser meldet einen erfolgreichen Script-Aufruf.
Da der Aufruf erfolgreich war [ich bin als Pascal Landau eingeloggt], muss eine der Profil-URLs bereits richtig sein, deshalb teile ich nun die Profile in die beiden Gruppen 0 [(1),(2),(3)] sowie 1 [(4),(5),(6)] auf und teste erneut wie folgt:
- Erlaube den Zugriff auf https://www.facebook.com/me und die folgenden 3 Profil-URLs via CSP Header
(1) https://www.facebook.com/JohnDoe1
(2) https://www.facebook.com/JohnDoe2
(3) https://www.facebook.com/pascal.landau1 - Erzeuge eine <script>-Element mit src=https://www.facebook.com/me
- https://www.facebook.com/me erzeugt eine Weiterleitung auf https://www.facebook.com/pascal.landau1 und der Browser meldet einen erfolgreichen Script-Aufruf.
Da der Aufruf erneut erfolgreich war, muss eine der Profil-URLs bereits richtig (also in Gruppe 0 [(1),(2),(3)] enthalten) sein, deshalb teile ich nun die Profile aus Gruppe A erneut in die beiden Gruppen 00 [(1),(2)] sowie 01 [(3)] auf und teste wie folgt:
- Erlaube den Zugriff auf https://www.facebook.com/me und die folgenden 2 Profil-URLs via CSP Header
(1) https://www.facebook.com/JohnDoe1
(2) https://www.facebook.com/JohnDoe2 - Erzeuge eine <script>-Element mit src=https://www.facebook.com/me
- https://www.facebook.com/me erzeugt eine Weiterleitung auf https://www.facebook.com/pascal.landau1, diese URL ist aber nicht mehr im CSP Header angegben und kann deshalb nicht aufgerufen werden. Folge: Der Browser meldet einen fehlgeschlagenen Script-Aufruf.
Da der Aufruf dieses mal fehlgeschlagen ist, war die richtige Profil-URL nicht in Gruppe 00 [(1),(2)] enthalten. Da die Prüfung zuvor mit [(1),(2),(3)] aber erfolgreich war, muss das Profil in Gruppe 01 [(3)] enhalten sein, deshalb teste ich nun wie folgt:
- Erlaube den Zugriff auf https://www.facebook.com/me und die folgende Profil-URL via CSP Header
(3) https://www.facebook.com/pascal.landau1 - Erzeuge eine <script>-Element mit src=https://www.facebook.com/me
- https://www.facebook.com/me erzeugt eine Weiterleitung auf https://www.facebook.com/pascal.landau1 und der Browser meldet einen erfolgreichen Script-Aufruf.
Damit habe ich „mich“ erfolgreich aus einer Gruppe von ursprünglich 6 unterschiedlichen Profilen identifiziert. Dazu brauchte ich jedoch keine 6 Versuche (= HTTP Requests) sondern nur 4. Das hört sich erstmal nach keiner besonders großen Verbesserung an, allerdings erfolgt die Reduktion gemäß der Formel
i = floor(log2(n - 1)) + 2 for n > 1 and i = 1 für n = 1; mit n = Anzahl aller Profile und i = Anzahl HTTP Requests
Oder anders: Die Anzahl der benötigten Requests entspricht ungefähr dem dualen Logarithmus über die Anzahl der Profile – und damit haben wir letztendlich eine Art binäre Suche implementiert. O(log(n)) ftw 😉
Zur Verdeutlichung eine kleine Tabelle:
| n (Anzahl getesteter Profile) | i (benötigte HTTP Requests) |
|---|---|
| 1 | 1 |
| 10 | 5 |
| 100 | 8 |
| 1.000 | 11 |
| 10.000 | 15 |
| 100.000 | 18 |
| 1.000.000 | 21 |
| 1.000.000.000 | 31 |
Das sieht doch schon besser aus: Mit dieser Methode können wir selbst 1 Milliarde URLs in knapp 30 HTTP-Requests testen!
Schwergewicht: Hohes Datenvolumen beim Bruteforcing
Leider hat aber auch diese Methode einen Pferdefuß :/ Um die einzelnen Profil-URLs testen zu können, müssen diese auf den Browser des Users übertragen werden. Selbst bei einer sehr positiven Einschätzung entstehen bei sehr vielen Profil-URLs enorme Datenvolumen. Nehmen wir mal an, es gäbe ein Social Network mit 1 Milliarde Nutzern, dessen Profil-URLs numerisch aufgebaut wären (https://www.facebook.com/0000000001, https://www.facebook.com/0000000002, etc.). Eine Profil-URL bestünde damit konstant aus 35 Zeichen. Gehen wir weiter davon aus, ein Zeichen benötigt 1 Byte Speicherplatz, dann wären das 1 x 35 x 1.000.000.000 Byte = ~32,6 GB an Daten! Selbst bei weiterer Optimierung durch Speicherung der reinen Pfad-Information (z.B. 0000000001 statt https://www.facebook.com/0000000001) bleiben 1 x 10 x 1.000.000.000 Byte = ~9,3 GB übrig.
Zum Glück lassen sich diese Daten z.B. durch gzip noch weiter komprimieren. Das klappt auch vor der Übertragung zum Browser und lässt sich meist relativ einfach aktivieren (bei Apache z.B. über das mod_deflate Modul – das sollte bei textbasierten Inhalten sowieso standardmäßig aktiviert werden).
Ich habe das testweise via PHP mit gzip simuliert:
<?php
$groupFolder = __DIR__ . "/groups";
if (! file_exists ( $groupFolder )) {
mkdir ( $groupFolder );
}
$sizes = array(1000,10000,100000,1000000);
foreach($sizes as $size){
$j= 0;
$file = "$groupFolder/t_$size.gz";
$fp = gzopen ($file , 'w9' );
while ( $j < $size ) {
$j++;
gzwrite ( $fp, sprintf("%1$010d",$j) );
}
gzclose ( $fp );
}
?>
| Anzahl IDs | ~Datenvolumen unkomprimiert | ~Datenvolumen komprimiert |
|---|---|---|
| 1.000 | 9,7 KB | 2 KB |
| 10.000 | 97 KB | 21 KB |
| 100.000 | 977 KB | 218 KB |
| 1.000.000 | 9,54 MB | 2,1 MB |
Selbst bei „nur“ einer Millionen Profile entsteht ein komprimiertes Datenvolumen von mehr als 2 MB bei einem Kompressionsfaktor von 5:1 – und dabei handelt es sich um konstruierte Werte mit sehr günstigen Parametern (Profil-URLs fortlaufen numerisch mit vielen führenden Nullen [lässt sich sehr gut komprimieren]). Das führt zum einen zu langen Übertragungszeiten und verursacht zum anderen sehr viel Traffic (denkt an volumensbasierte Tarife…).
In der Praxis stoßen wir hier definitiv an eine Grenze! Das Problem kann aus meiner Sicht nur gelöst werden, indem eine sinnvolle Vorauswahl der zu überprüfenden Profile vorgenommen werden kann.
Vorqualifizierung von Facebook Profil URLs
Die Lösung dieses Problems stellt die Kür dieser Deanonymisierungstechnik dar und leider habe ich dafür noch keine universelle Lösung gefunden. Trotzdem möchte ich ein paar Gedanken dazu loswerden:
Lokationsinformationen
Als Einschränkungsmerkmal zur Vorqualifikation kann potenziell alles dienen, was uns etwas über den Nutzer verrät. Spontan fallen mir dazu vor allem zwei Informationen ein: IP-Adresse und Browsersprache:
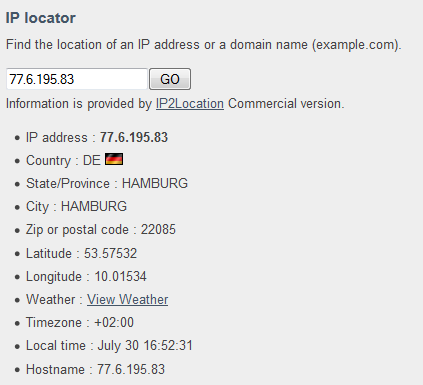
Über die IP-Adresse lässt sich potenziell der Standort des Nutzers ermitteln (zum Beispiel mit der öffentlichen & kostenlosen API von IPInfoDB), der dann wiederum gegen den Wohnort eines Facebook Users gematcht werden kann. Das setzt natürlich voraus, dass man auf auf den Wohnort Zugriff hat (auf dieses Problem gehe ich im nächsten Abschnitt ein).

Über die Browsersprache kann versucht werden, eine Einschränkung über die Facebook-Spracheinstellung des Users vorzunehmen (auch hier => nächster Abschnitt). Dazu muss geprüft werden, ob der HTTP Header „Accept-Language“ bei der Anfrage mitgesendet wird.
Erstellung eines Gruppen-Fingerprints
Das unter Related Work aufgeführte Paper A Practical Attack to De-Anonymize Social Network Users verfolgt ebenfalls den Ansatz einer Vorqualifizierung. Es wird an Hand der Browser History geprüft, welche (Xing-)Gruppen ein Nutzer aufgerufen hat und an Hand dessen die Suche auf die Mitglieder dieser Gruppen eingeschränkt.
Dadurch muss eben nicht mehr jedes Profil getestet werdern sondern „nur noch“ alle Gruppen, wobei sich auch diese wieder einschränken lassen (große Gruppen vermeiden, Nutzer-Überlappungen berechnen und redundante Gruppen entfernen, etc.). Dieses Prinzip lässt sich vermutlich auch auf Facebook anwenden. Das im Paper beschriebene History Stealing funktioniert bei aktuellen Browsern nicht mehr, und ich konnte auch keinen CSP-basierten Ansatz finden.
Die vielverprechendste Methode wäre die Prüfung der URL https://www.facebook.com/ajax/groups/members/add_get.php?group_id=[groupId]&email=1, die einen Status Code 200 bei Gruppenmitgliedern liefert, während bei Nicht-Mitgliedern ein Status Code 404 zurückgegeben wird. Diese Information lässt sich auf eine ähnliche Weise bekommen wie beim CSP-Exploit. Im Prinzip muss man lediglich ein <script>-Element erzeugen und dess src-Attribut auf https://www.facebook.com/ajax/groups/members/add_get.php?group_id=[groupId]&email=1 setzen und prüfen ob der daraus resultierend Request erfolgreich ist. Allerdings benötigt man dabei 1 HTTP Request pro zu prüfender Gruppe – was leider nicht gut skaliert…
Vordefinierte Benutzergruppen
Nehmen wir mal an, eine Organisation (NSA, BND, etc) wäre an einer bestimmten Gruppe von Personen interessiert und hat deren Facebook-Profile bereits identifziert. Mit der hier vorgestellten Methode wäre es möglich, einen bei Facebook eingeloggten Benutzer aus dieser Gruppe zu identifizieren, wenn dieser eine entsprechend präparierte Webseite aufruft. Jetzt muss er nur noch getaggt werden und kann von da an auf jeder von der Organisation kontrollierten Seite wiedererkannt werden. Ich muss also nur dafür sorgen, dass eine solche Person irgendwie auf einer infizierten Seite landet…
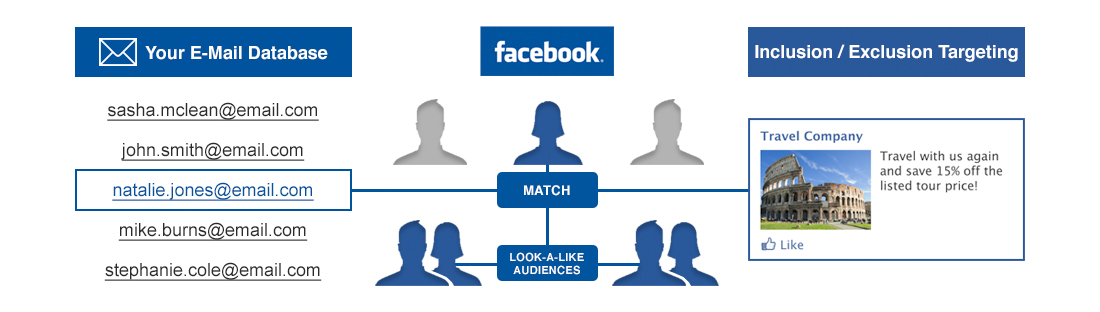
Wer auf der Campixx 2014 war, der wird zweifellos von Nedims Vortrag Der Weg zur ersten Million gehört haben. Der springende Punkt dabei war, dass über ein geschicktes Scraping der Mitgliedslisten von Facebook-Gruppen (in Form von User IDs) gezielt Nutzer mit bestimmten Interessen ermittelt werden können. Interessant wird das dann, wenn diese Informationen zur Schaltung von Facebook Ads durch das Custom Audience Targeting benutzt werden, da dadurch ein sehr niedriger CPC bei sehr hohem Targeting erreicht werden kann. Ein gut erklärtes Beispiel dazu liefert der Artikel Der (steinige) Weg zur ersten Million auf Facebook.
Angenommen wir würden eine solche Kampagne aufsetzen, dann hätten wir gleichzeitig auch eine sehr gute Einschränkung auf die entsprechenden Facebook-Profile. Wir müssen lediglich noch die Facebook User IDs auf die entsprechenden Profile auflösen…
Datenbasis: Beschaffung von Facebook Profil-URLs und weiteren Daten
Bisher bin ich stillschweigend davon ausgegangen, ich hätte sämtliche Profilinformationen aller Facebook-Nutzer zur Verfügung. Das ist natürlich aus mehreren Gesichtspunkten utopisch: Eine komplette Ermittlung aller (mehr als) eine Milliarde User ist allein schon aus Sicht der Ressourcen zur Ermittlung eine nicht zu unterschätzende Aufgabe – schließlich wird man kaum einen Komplettexport zum Download bekommen. Um trotzdem an die Daten zu kommen, gibt es zwei mögliche Ansatzpunkte: Die Facebook Graph-API und das Crawling der Weboberfläche.
Achtung: Das massenhafte Scrapen von Nutzerdaten ist verboten und wird hier nur zu Bildungszwecken erläutert!
Facebook Graph API
Interessant ist hier vor allem die User Tabelle, die wir einfach via http://graph.facebook.com/[User ID] (häufig auch Facebook uid genannt) oder http://graph.facebook.com/[Username] ansprechen können.
Beispiel-Antwort für die Anfrage https://graph.facebook.com/1144346144 bzw. http://graph.facebook.com/pascal.landau1:
{
"id": "1144346144",
"first_name": "Pascal",
"gender": "male",
"last_name": "Landau",
"link": "https://www.facebook.com/pascal.landau1",
"locale": "de_DE",
"name": "Pascal Landau",
"username": "pascal.landau1"
}
Über das „locale“-Feld kann ich an dieser Stelle übrigens die oben erwähnte Einschränkung der möglichen Profile durch ein Matching über die Browsersprache versuchen.
Noch effizienter geht es über eine FQL Abfrage mit einem IN Statement für die User IDs oder Usernamen. So liefert zum Beispiel die Abfrage https://graph.facebook.com/fql?q=select first_name,last_name,uid,profile_url,sex,locale,username+from+user+where+uid+in+(4,1144346144) bzw. https://graph.facebook.com/fql?q=select first_name,last_name,uid,profile_url,sex,locale,username+from+user+where+username+in+(„zuck“, „pascal.landau1“) folgendes Ergebnis:
{
"data": [
{
"first_name": "Mark",
"last_name": "Zuckerberg",
"uid": 4,
"profile_url": "https://www.facebook.com/zuck",
"sex": "male",
"locale": "en_US",
"username": "zuck"
},
{
"first_name": "Pascal",
"last_name": "Landau",
"uid": 1144346144,
"profile_url": "https://www.facebook.com/pascal.landau1",
"sex": "male",
"locale": "de_DE",
"username": "pascal.landau1"
}
]
}
Durch Experimentieren habe ich eine Grenze von 5000 Ergebnissen pro Abfrage ermittelt, wenn entsprechend viele User IDs im IN Statement übergeben werden. Theoretisch bräuchten wir also „nur“ ca. 1.000.000.000/5000 = 200.000 Abfragen um die Facebook Userdaten abzufragen – nicht wenig aber auch keinesfalls unmachbar.
Leider hat diese Methode das große Problem, dass wir bereits vorab die genauen User IDs bzw. Username benötigen – und diese sind (auch wenn es den Anschein hat) nicht sequenziell erzeugt worden. Sprich einfach „Hochzählen“ klappt nicht. Nach einiger Recherche bin ich auf den Quora Thread Facebook Company History: What is the history of Facebook’s user ID numbering system? gestoßen, in Kürze:
Früher gab es Nummernkreise für einzelne Universitäten mit bis zu 100.000 möglichen User IDs pro Uni. Ein solcher Nummernkreis wird aus Uni-Prefix + sequenzielle ID gebildet. Columbia hat zum Beispiel das Prefix 1 und der erste Facebook User dieser Uni war Sasha Katsnelson mit der Facebook uid 100002. Eine Übersicht der (bekannten) Präfixe gibt es in dem Quora Thread Facebook Company History: In what order did Facebook open to college and university campuses?. Leider wurde dieses System laut einem Facebook-Sprecher umgestellt:
We assigned numerical blocks in the early days, but today user IDs are not issued sequentially. We draw them from a variety of number ranges.
Möglicherweise kann man auch die aktuellen Präfixe reengineeren aber darum habe ich mich noch nicht weiter bemüht 🙂
Crawling der Facebook Weboberfläche
Hier liefert A Practical Attack to De-Anonymize Social Network Users wieder sehr gute Ideen.
Zum Scrapen aller öffentlichen Facebook Profile empfiehlt sich ein Start im Personenverzeichnis von Facebook. Hier sind alle öffentlichen Profile in einer Baumstruktur verlinkt und können dadurch einfach gescraped werden. Aus Effizienzgründen könnte man auch nur die Usernamen von einer unteresten Ebene (z.B. https://www.facebook.com/directory/people/A-1-120) extrahieren und mit diesen dann eine Abfrage gegen die Facebook Graph API starten um die Daten noch um „locale“ und Co. zu ergänzen – dann spart man sich das Scraping einzelner Profilseiten.
Ein zweiter Weg geht über die Personensuche. Dazu ist zwar ein Login erforderlich, aber dafür lassen sich die Suchergebnisse an Hand von Filtern einschränken – unter anderem durch den Wohnort! In Kombination mit der Standort-Information aus der IP Adresse kann damit eine ordentliche Einschränkung vorgenommen werden.
Grobes Vorgehen wäre hier:
- Liste der häufigste Vornamen besorgen (siehe hier oder hier)
- Liste der größten Städte besorgen (siehe hier)
- Suche nach dem ersten Namen in der Namensliste
- Setze den „Wohnort“-Filter auf die erste Stadt der Städteliste
- Scrape die Ergebnisse
- Wiederhole mit der nächsten Stadt (GOTO 4)
- Wiederhole mit dem nächsten Namen (GOTO 3)
In der Theorie einfach, in der Praxis auf Grund der stark AJAX-abhängigen Implementierung leider etwas komplizierter, dank Tools wie CasperJS aber nicht unmöglich. Über die Suchfunktion der API scheint eine Einschränkung auf den Wohnort leider nicht möglich zu sein.
Grundproblem: Browser-Implementierung des Content-Security-Policy Headers
Die hier gezeigte Deanonymisierungstechnik funktioniert nur, weil es im CSP Header möglich ist, URLs auf Pfad-Ebene zu erlauben. Das entspricht jedoch nicht der ersten Version der CSP Spezifikation vom W3C. Dort wird unter dem Punkt 3.2.2 Source List lediglich eine Verifizierung auf Host-Ebene vorgeschlagen. In diesem Falle ist es nicht möglich, auf eine konkrete Facebook Profil URL zu testen – also nicht https://www.facebook.com/pascal.landau1 sondern eben nur https://www.facebook.com/. Das ist aber für den oben beschriebenen Deanonymisierungsvorgang nicht ausreichend.
Erst mit CSP 1.1 (noch im Draft-Status) wird die Prüfung bis auf Pfad-Ebene eingeführt. Dass das zu Privay-Problemen führen kann, hat Egor Homakov bereits im Januar diesen Jahres bemerkt und darüber in Using Content-Security-Policy for Evil gebloggt. Daraufhin wurde eine Diskussion zur Vermeidung dieser Sicherheitslücke begonnen, die (vorläufig) zu einer Sonderbehandlung von Redirects im aktuellen Working Draft der CSP 1.1 Spezifikation geführt hat (siehe Punkt 4.2.2.3 Paths and Redirects). Durch diese Anpassung wird die Validierung nach einem Redirekt auf den Host beschränkt, wodurch effektiv vermieden wird, dass wir Facebook Profile identifizieren können.
Heißt das, dass es gar nicht funktioniert?
Nein, heißt es nicht. Denn die aktuelle Version ist vom 2 Juli 2014 und in der Vorgängerversion des CSP 1.1 Drafts fehlt der „Paths and Redirects“ Part und damit auch der Fix. Diese Vorgängerversion wird zum Beispiel im aktuellen Chrome-Browser (Chrome 36) umgesetzt und obwohl es bereits seit Oktober 2013 einen entsprechenden Chrome-Bugreport gibt, hat sich noch nichts geändert.
Und die anderen Browser?
Browser, die CSP 1.0 umsetzen, können für diese Deanonymisierungstechnik nicht genutzt werden und Browser, die den aktuellsten Draft von CSP 1.1 umsetzen ebenfalls nicht. In meinem Test hat der Internet Explorer (IE11) den Content-Security-Header komplett ignoriert und der Firefox (FF30.0) lediglich CSP v1 implementiert. Nur Google Chrome (36; vermutlich seit 25) hält sich an dei veraltete CSP 1.1 Spec. Die Can I use… Übersicht zur Content-Security-Policy ist leider nur bedingt hilfreich, weil sie keinen Hinweis auf die CSP Version gibt…
Aber in Zukunft wird CSP-Deanonymisierung nicht mehr funktionieren?
Richtig, wenn sich die Browserentwickler bei der Implementierung des Content-Security-Headers an den aktuellen Arbeitsstand halten, dann wird diese Deanonymisierungstechnik nicht mehr klappen.
Gibt es noch weitere Einschränkungen?
Das Prinzip basiert grundsätzlich darauf, dass der Browser Third-Party-Cookies zulässt – sonst könnte man nicht abfragen ob man bei Facebook eingeloggt ist. Allerdings funktionieren dann auch keine (legitimen) Like-Buttons etc.
Warum dann der ganze Aufwand?
Die ehrliche Antwort? Ich habe zunächst nur gedanklich einen möglichen Angriff durchgespielt und dann durch Try & Error rausgefunden, dass der aktuelle Chrome anfällig dafür ist. Danach wollte ich testen, ob sich daraus ein reales Deanonymisierungsszenario konstruieren lässt, dass tatsächlich in der Praxis funktioniert. Den aktuellen Draft, bei dem bereits der Fix zur Vermeidung des Angriffs vorgeschlagen ist, habe ich leider erst im Nachhinein gelesen 🙁
TL;DR: CSP-Deanonymisierung funktioniert nur in Ausnahmefällen
Die hier beschriebene Methode funktioniert in meinen bisherigen Tests ausschließlich in Google Chrome auf Grund dessen Umsetzung der veralteten CSP 1.1 Spec.
Weiterhin ist sie in der Praxis nur dann anwendbar, wenn eine Vorauswahl der zu testenden Facebook Profil URLs getroffen werden kann, da sonst die zu übertragende Datenmenge zu groß ist und der ganze Prozess zu lange dauert. In meinem Test habe ich das richtige Profil aus einer Liste von 100.000 Profil-URLs in ca. 25 Sekunden bei einem Datenvolumen von 2 MB herausfinden können.
Proof of Concept – Tool zur Deanonymisierung in der Praxis
Die Theorie hinter der CSP-Deanonymisierung habe ich in nahezu epischer Breite erläutert, jetzt geht’s an’s Eingemachte. Dazu habe ich ein Tool entwickelt, das als Proof of Concept zur Deanonymisierung dient und dass ich im Folgenden beschreiben werde.
Wie benutzt man das Tool?
Im ersten Schritt werden die Voraussetzungen für das Funktionieren des POCs definiert:
- Du benutzt Google Chrome (Version 25 bis 36 [aktuelle Version])
- Du hast Third-Party-Cookies nicht deaktiviert
- Du bist bei Facebook eingeloggt
Einschränkung der Profile
Im zweiten Schritt gibt es eine kurze Erläuterung zur Funktionsweise, die ich hier noch ausführlicher darstellen möchte. Ich habe davon abgesehen, „echte“ Facebook-Nutzerprofile zur Prüfung zu hinterlegen, da mir das rechtlich einfach zu unsicher ist. Und für einen Rechtsstreit mit Facebook fehlt mir eindeutig das nötige Kleingeld 😉 Allerdings habe ich ja beschrieben, dass das zu deanonymisierende Profil zwingend vorhanden sein – sonst kann ich es schließlich nicht finden…
Um dieses Problem zu umgehen wird ein Textfeld zur Verfügung gestellt, in das das „richtige“ Profil eingegeben werden muss. Zusätzlich sollten noch eine Reihe anderer Profile eingegeben werden, damit ausgeschlossen werden kann, dass das Tool einfach nur die vom Nutzer eingegebene „richtige“ URL aus dem Textfeld ausliest.
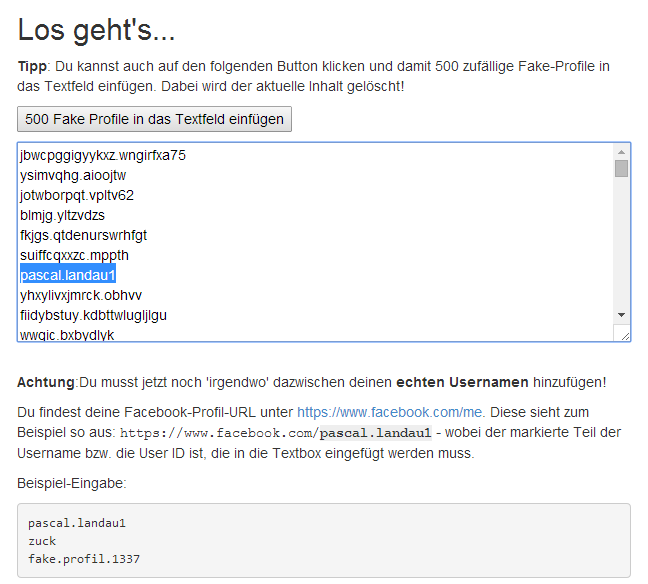
Das Tool benutzt dann den Inhalt des Textfeldes als Datenbasis für das CSP-Header-Bruteforcing. In der Praxis würde man stattdessen wie oben beschrieben eine Vorqualifizierung von Facebook Profil URLs vornehmen.
Natürlich ist das suboptimal, weil dieser Schritt bei einer realen Attacke nicht stattfindet. Trotzdem hoffe ich, dass ich einen anständigen Trade-Off zwischen „Das Tool funktioniert in der Praxis“ und „Ich will nicht von Facebook wegen unbefugten Scrapings verklagt werden“ gefunden habe 🙂
Für alternative Vorschläge bin ich natürlich offen!
Funktionsweise
Nachdem die Frage der Datenbasis geklärt ist, kann endlich der Prozess zur Deanonymisierung gestartet werden.
Technisch habe ich die CSP-Tests mit Hilfe von dynamisch erzeugten Iframes gelöst, in die eine CSP-Directive via <meta>-Element geschrieben wird und im Anschluss versucht wird, ein <script>-Element zu laden. Das Ergebnis des <script>-Aufrufes wird dann via postMessage zurück an das Parent-Window geliefert. Hier die entsprechende Funktion:
function checkUrl(obj){
var err = {
'phase' : obj.phase,
'name' : obj.name,
'next' : obj.next,
'value' : obj.errorValue,
'info' : obj.info
}
var suc = {
'phase' : obj.phase,
'name' : obj.name,
'next' : obj.next,
'value' : obj.successValue,
'info' : obj.info
}
var csp = obj.csp;
var url = obj.url;
var iframe = document.createElement("iframe");
iframe.style.display = "none";
document.body.appendChild(iframe);
var html = '<!DOCTYPE HTML><html><head><meta charset="utf-8" /><meta http-equiv="Content-Security-Policy" content="'+csp+'"></head><body><script src="'+url+'" onerror=parent.postMessage('+JSON.stringify(err)+',"*") onload=parent.postMessage('+JSON.stringify(suc)+',"*") ><'+'/script></body></html>';
iframe.contentWindow.document.open();
iframe.contentWindow.document.write(html);
iframe.contentWindow.document.close();
}
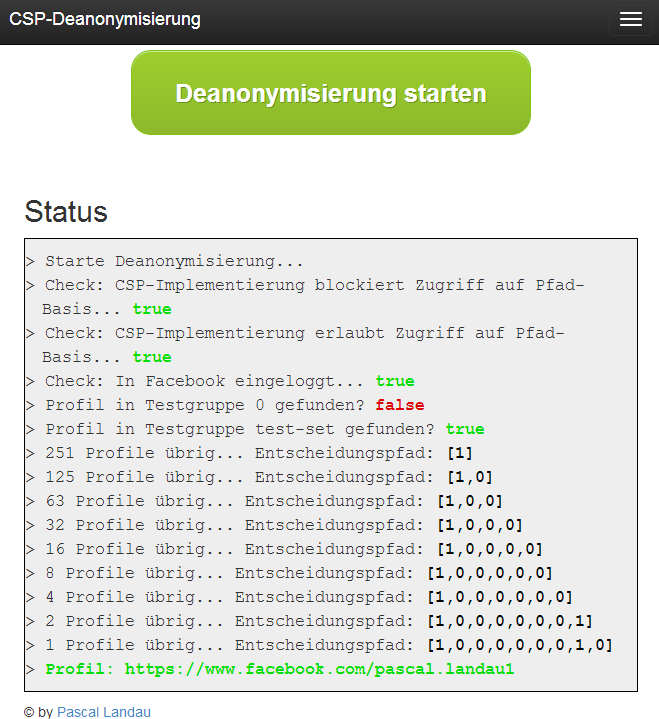
Der Prozess besteht im Wesentlichen aus 6 Schritten:
1. Schritt – Prüfen ob der Browser angreifbar ist
Hier wird geprüft, ob CSP 1.0 oder CSP 1.1 eingesetzt wird (oder keines von beiden).
2. Schritt – Prüfen ob der Nutzer eingeloggt ist
Das ist genau die Prüfung, die unter Login-Status prüfen beschrieben ist.
3. Schritt – Simulation eines realen Szenarios
Hier teste ich 1.000 Fake-Profile um eine realistische Dauer sowie Datenmenge zu simulieren. Diese Prüfung wird natürlich immer fehlschlagen, aber in einem realen Angriff wären das meine vorqualifizierten Profile. [Dieser Schritt ist für das POC eigentlich unnötig. In einer früheren Version habe ich 100.000 Fake-Profile getestet, aber das hat der Chrome auf meinem S3 nicht mitgemacht.]
4. Schritt – Prüfung aller Profile im Textfeld
Es wird getestet, ob sich die richtige Profil-URL im Textfeld befindet.
5. Schritt – Binäre Reduktion der Profile
Das ist der Prozess, der unter Binäre Suche über Profil-URLs beschrieben ist. Dazu verwende ich folgende PHP Funktion:
<?php
function BinaryArraySearch(array $arr, array $bitmask){
$leftSlice = $arr;
while(count($bitmask) > 0 && count($leftSlice) > 1){
$length = ceil(count($leftSlice)/2);
$rightSlice = array_splice($leftSlice, $length);
$b = array_shift($bitmask);
if($b == 1){
$leftSlice = $rightSlice;
}elseif($b === null && count($bitmask) == 0){
$leftSlice = array_merge($leftSlice, $rightSlice);
}elseif($b != 0){
throw new Exception("'$b' is not a valid bit flag, use either '0' or '1'");
}
}
return $leftSlice;
}
?>
6. Schritt – Ergebnisanzeige
Am Ende der binären Suche wird die vollständige Profil-URL ausgegeben.
Hier noch einmal der Link zum Tool.
Scope, How-to-fix und Responsible Disclosure
Während der Programmierung des Tools ist mir aufgefallen, dass ich durch minimale Anpassungen nicht nur Nutzer von Facebook, sondern auch von Xing (Xing hat am 05.08.2014 einen Fix deployed), Google Plus und Youtube deanonymisieren kann. Und vermutlich gibt es noch eine ganze Reihe weiterer anfälliger Webseiten. Bei Twitter und LinkedIn konnte ich übrigens spontan nichts finden.
Die Netzwerke selbst können leider nur wenig gegen diese Deanonymisierungstechnik unternehmen. Solange es eine Weiterleitung via Location-Header auf die Profil-URL eines eingeloggten Nutzers gibt, kann diese durch CSP-Bruteforcing ermittelt werden.
Ein erster Quickfix wäre die Umstellung auf eine JavaScript- bzw. Meta-Refresh-basierte Weiterleitung – zumindest für den Google Chrome. Facebook macht das für den Internet Explorer sogar jetzt schon. Ich halte das zwar aus Entwickler-Sicht für einen schlechten Stil, aber es würde die Attacke effektiv unterbinden.
Außerdem sollte es so schwer wie möglich sein, eine Vorqualifizierung der Profile vorzunehmen. Das dürfte aber extrem schwierig umzusetzen sein, denn zumindest die „Ich scrape die uids einer bestimmten Gruppe und schalte darauf Facebook-Ads“-Methode lässt sich eigentlich nicht verhindern. Durch die nicht-sequenzielle Vergabe der User-IDs und die doch recht spärlichen Informationen aus der API ist Facebook hier bereits einigermaßen gut aufgestellt (allerdings habe ich in diesen Part auch nicht allzu viel Zeit investiert…)
Responsible Disclosure
Der Exploit betrifft zwar aktuell nur den Chrome Browser und wird wohl in Zukunft gefixt, aber dennoch sollten zumindest die großen Netzwerke explizit vorab informiert werden – vor allem wenn ich öffentlich darüber berichte. Deshalb habe ich mich an Facebook, Chrome, Google Plus, Youtube und Xing gewandt und halte im Anschluss die Kommunikation fest:
Bekannt, won’t fix – siehe Konversation
Bekannt, won’t fix – siehe Konversation
Fixed – siehe Konversation
Fazit: Viel gelernt aber nixnur wenig gewonnen
Was bleibt nach mehr als 4500 Worten, ein paar hundert Zeilen Code und etlichen Stunden Try & Error? Generell fand ich es sehr spannend, einen Exploit (fast) vollständig zu dokumentieren und als POC zur Verfügung zu stellen.
Ein gewisser fader Beigeschmack bleibt aber, weil das Problem bereits bekannt und in der aktuellen CSP 1.1 Spezifikation „gelöst“ ist. Trotzdem ist es aus meiner Sicht ein praxisrelevanter Use-Case, der hoffentlich durch diesen Artikel noch einmal stärker ins Bewusstsein gerückt wird. Außerdem heißt „es steht in der Spec“ noch lange nicht „es wird so vom Browser implementiert“ 😉
Und jetzt freue ich mich auf Feedback, Fragen und Anregungen – oder einen Share/Tweet auf einem sozialen Netzwerk eurer Wahl 🙂